[자료구조] 해시맵(Hash Map) 해시

목차
1. 해시맵
2. 해시와 해시 함수
3. capacity & load factor
4. 구현
해시맵(Hash Map)
개념
맵이란 것은 키(Key) 와 값(Value) 두 쌍으로 데이터를 보관하는 자료구조. (키는 맵에 오직 유일하게 있어야함 ,값은 중복 상관 X). 키와 값을 매핑하기 위해 해시라는 것을 사용한다. 한편,HashMap은 HashTable과 달리 보조 해시 함수(Additional Hash Function)를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌(hash collision)이 덜 발생할 수 있어 상대적으로 성능상 이점이 있다. (해시 테이블과의 비교는 사실 의미 없음)
특징
java 8 HashMap에서는 Entry클래스 대신 Node 클래스를 사용한다. 링크드 리스트 대신 트리를 사용할 수 있도록 하위 클래스인 TreeNode가 있다는 점에서 java 7 HashMap과 다르다. 이 때 사용되는 트리는 Red-Black Tree이다.
해시와 해시 함수
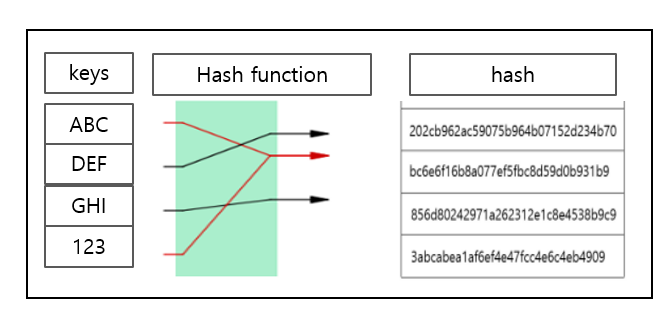
해시는 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 값이다. 이를 매핑하기 위해 있는 것이 해시 함수이다.
예를들어 {"ABC","1"}, {"DEF","2"}, {"GHI","3"}, {"123","4"} 라는 값이 해시 맵에 들어간다고 하면 아래와 같이 저장된다.
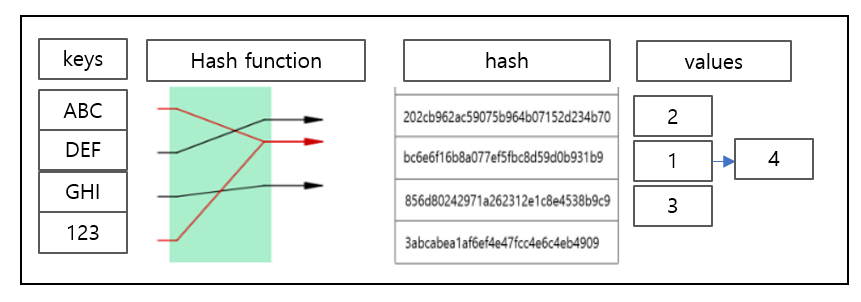
각각 hash에 매핑되어 value가 들어가게 되고, 만약 같은 hash값을 가진다면 링크드 리스트 형태로 저장되게 된다.
Q) 1대1 대응으로 O(1)의 시간복잡도를 하면되지 왜 링크드 리스트 형태로 저장되나요?
해시는 O(1)을 보장하기 위함이지만, 이는 완전한 자료 해시 함수일 때만 가능하다.(각각 모두 달라야함) 자바의 HashMap에서는 hashCode() 결과 자료형이 int 32비트 정수 자료형이다. 32비트 정수 자료형으로는 완전한 자료형을 만들 수 없다.( 객체가 2^32보다 많다면 1대1 매핑 할 수 없음). 또한 32비트만이라고 하더라도, O(1)을 보장하려면 모든 해시맵이 2^32인 배열을 가지고 있어야하는데, 이렇게 되면 메모리를 많이 사용하게 된다. 따라서 객체에 대한 해시코드의 나머지 값을 버킷의 인덱스로 사용한다.
int index = X.hashCode() % M;이렇게 되면 서로 다른 해시 코드를 가지는 서로 다른 객체가 같은 해시 버킷을 사용하게 될 확률은 1/M가 된다. 이렇게 겹치게 되는 상황을 링크드 리스트를 통해 해결하게 되는 것이다. 이를 Separate Chaining이라고 한다. (위의 1 -> 4)
Q) 객체의 해시 함수 값이 균등 분포상태라고 할 때, get으로 값을 꺼낼 때 기대되는 시간 복잡도는?
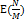
N = 12, M = 3인경우 링크드리스트를 4번 탐색해야한다.

하지만 자바8에서는 데이터의 개수가 많아지면 링크드 리스트 대신 트리를 사용한다. 따라서 시간 복잡도는 아래와 같다.
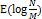
하나의 해시 버킷에 8개의 키 값 쌍이 모이면 링크드 리스트를 트리로 변경하고, 개수가 다시 6개에 이르면 다시 링크드 리스트로 변경한다. 트리는 링크드 리스트보다 메모리 사용량이 많기 때문이다.
Capacity & Loadfactor
개요
해시맵에서 값을 찾는 데에 걸리는 시간은 hash의 총 길이와 그 사이즈(링크드 리스트를 참조해야하므로)에 비례한다. 따라서 이를 관리하기 위해 Capacity와 Loadfactor라는 개념이 등장한다.
설명
capacity란 hash의 총 길이(버킷의 개수)이고, loadfactor는 capacity 중 몇 개가 매핑되어있는지를 나타내는 비율이다.
예를 들어 맨 위의 해시 사진의 경우 capacity는 4이고, 매핑된 것이 3개이므로 loadfactor는 3/4 = 0.75 이다. 하지만 위의 사진에서 추론해볼 수 있듯이, capacity가 너무 작으면, key value가 추가될 때마다, 링크드 리스트가 길어질 확률이 높다. 이러면 해시로 값을 찾기 위해 시간이 많이 걸릴 것이다. 따라서 보통의 경우 capacity는 16, loadfactor는 0.75가 기본 설정이다.
해시 버킷 동적 확장
1)개요
해시 버킷의 수가 작으면, 메모리 사용을 아낄 수 있지만, 링크드 리스트가 길어져 시간이 오래걸리고 해시 충돌로 성능 손실이 발생한다. 그래서 키-값의 데이터 개수가 일정 개수 이상이 되면 해시 버킷의 개수를 두배로 늘리게 된다.
2)문제점과 해결
그러나 이렇게 해시 버킷을 두 배로 확장하는 것에는 결정적인 문제가 있다. 해시 버킷의 개수 M이 2*a의 형태가 되기 때문에,
int index = X.hashCode() % M;이를 계산할 때, X.hashCode()의 하위 a개 비트만 사용하게 된다. 해시 함수가 32비트 영역을 고르게 사용하도록 만들었다고 해도, 해시 값을 위와 같이 나누게 되면 해시 충돌이 발생할 확률이 높아진다. 이를 해결하기 위해 보조 해시 함수가 있다.
3)자바 8에서 보조해시 함수
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
하위 a개만 사용하게 되는 단점이 있으므로, 상위 비트의 값이 반영될 수 있도록 하는 코드라고 이해하면 된다.
Q)해시 값을 위와 같이 나누게 되면 해시 충돌이 발생할 확률이 높아진다. 가 무슨 뜻인가요?
M이 16이라고 하면, 나머지는 0~15밖에 안되므로, 32비트의 해시가 나오게 해시 함수가 설정되어있어도, 0~15사이의 값이 계속나온다.
구현
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
#define MAX_TABLE 5 // 테이블 크기
#define MAX_KEY 8 // include null
#define MAX_DATA 12 // 해시테이블에 넣을 데이터의 수
#define DELETE_COUNT 6 // 삭제할 데이터의 수
#define FIND_COUNT 8 // 찾을 데이터의 수
struct Node {
char key[MAX_KEY];
int value;
Node* next;
};
Node* tb[MAX_TABLE]; // hash table
char* keys[MAX_DATA]; // key
int values[MAX_DATA]; // value
// hash 함수 간단 구현
int hash(const char* str) {
int hash = 401;
while (*str != '\0') {
hash = hash + (int)(*str);
str++;
}
return hash % MAX_TABLE;
}
// 문자열 복사
void my_str_cpy(char* dest, const char* src) {
while (*src != '\0') {
*dest = *src;
dest++; src++;
}
*dest = '\0';
}
// 문자열 비교
int my_str_cmp(const char* str1, const char* str2) {
while (*str1 != '\0' && (*str1 == *str2)) {
str1++;
str2++;
}
return *str1 - *str2;
}
// add
void add(const char* key, int value) {
// 새로운 node 초기화
Node* newNode = new Node();
my_str_cpy(newNode->key, key);
newNode->value = value;
int index = hash(key);
if (tb[index] == NULL) {
tb[index] = newNode;
}
//값이 있으면 앞에 링크드 리스트로 연결하기(해시 충돌 해결)
else {
Node* cur = tb[index];
while (cur != NULL) {
// key가 중복이면 값을 바꾸기
if (my_str_cmp(cur->key, key) == 0) {
cur->value = value;
return;
}
cur = cur->next;
}
// 중복 아니면 앞에 추가하기
newNode->next = tb[index];
tb[index] = newNode;
}
}
int get(const char* key) {
int index = hash(key);
Node* cur = tb[index];
while (cur != NULL) {
if (my_str_cmp(cur->key, key) == 0) {
return cur->value;
}
cur = cur->next;
}
}
bool pop(const char* key) {
int index = hash(key);
// 비어있다면, return False
if (tb[index] == NULL) {
printf("tb[%d]에 { %s }이 없습니다.(비어있음)\n", index, key);
return false;
}
// 첫번째
if (my_str_cmp(tb[index]->key, key) == 0) {
Node* firstNode = tb[index];
tb[index] = tb[index]->next;
printf("%s를 tb[%d]에서 지웠습니다.\n", firstNode->key, index);
// 메모리 해제
delete firstNode;
}
// 그 외
else {
Node* prev = tb[index];
Node* cur = tb[index]->next;
while (cur != NULL && my_str_cmp(cur->key, key) != 0) {
prev = cur;
cur = cur->next;
}
if (cur == NULL) {
printf("tb[%d]에 { %s }이 없습니다.\n", index, key);
return false;
}
prev->next = cur->next;
printf("%s를 tb[%d]에서 지웠습니다.\n", cur->key, index);
delete cur;
return true;
}
}
void print_hash() {
for (int i = 0; i < MAX_TABLE; ++i) {
if (tb[i] != NULL) {
printf("index: %d\n", i);
Node* cur = tb[i];
while (cur != NULL) {
printf("{ %s, %d }, ", cur->key, cur->value);
cur = cur->next;
}
printf("\n");
}
}
}
int main(void) {
add("apple", 5);
add("fruit", 6);
add("aaa", 3);
add("asdkn", 4);
pop("asfdss");
print_hash();
return 0;
}
참고
https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] 링크드 리스트 정리 및 구현 (2) | 2022.08.07 |
|---|---|
| [자료구조] 배열 구현하기 c++ (0) | 2022.08.06 |
| [자료구조] 힙(Heap)과 완전 이진 트리(Complete binary tree) 개념 및 구현 (0) | 2022.04.19 |