[운영체제] 페이징 기법
목차
1. 개념
2. 주소 매핑 동작 방식
3. Page fault
4. TLB
5. 2단계 페이징 기법

개념
논리 메모리와 물리 메모리를 동일한 크기로 분할해, 분할된 페이지 별로 메모리를 할당하는 것을 의미한다. 분할된 페이지에는 메모리가 하나의 덩어리 형태로 존재한다. 논리주소(VA)와 물리주소(PA)를 매핑하기 위한 page table이 존재하며, 각 페이지 안에서 페이지 부분의 상대적인 위치는 바뀌지 않는다.( 서울시 -> 제주도 but 번지수는 그대로). 미리 설명하자면 페이지의 상대적인 위치는 offset이다.
주소 매핑 동작 방식

예를 들어, Virtual Page Number 0은 0~4095의 주소를 가지고 있다. 이는 Page table에 매핑된 Physical Page Number 1로 매핑되게 된다. 여기서 offset이라는 페이지 내의 상대주소는 변하지 않고 매핑된다. 예를들어 가상 주소 4를 참조했었다면 물리 주소에서는 4096 + 4 의 위치를 참조하게 되는 것이다. 4라는 offset은 변하지 않는다.
앞서 설명한 것처럼 Page table에 의해 매핑된 주소를 찾을 수 있는데, 구체적으로 이는 어떻게 동작하는 것인지 아래의 사진을 보며 이해해보자.
Page Table

page table에는 VA와 PA가 저장되어 있어 매핑할 수 있게 된다. 예를 들어 0x0003번의 VA 주소는 0x0006번의 PA 주소에 매핑되어 있음을 알 수 있다. 따라서 VA -> PA로의 주소 변환이 가능하게 된다.
Q) VA가 총 2^20인 이유는 무엇인가?
한 페이지 당 4KB = 2^12이다. 32bit 컴퓨터안에서 총 용량 2^32 를 페이지 단위인 2^12로 나눠보자. 그러면 총 2^20개의 페이지가 있을 수 있음을 알 수 있다. 한편, offset은 페이지의 크기인 2^12가 된다. 4KB를 1bit단위로 잘게 쪼갠다고 생각하면, 구분할 수 있는 개수는 총 2^12개이기 때문이다.
Page fault
개념
가상 주소를 참조했는데 물리 메모리에 없는 것이 page fault이다.

예를 들어, Page 1의 4번지를 참조하려고 한다고 하는데, 참조할 페이지가 물리 주소에 올라와 있지 않으면 page default가 발생한다.
page default를 인식하는 원리
물리 주소에 매핑된 page가 있는지 없는지 체크하기 위해, 이를 알기 위해 invalid valid bit라는 것이 있다. 만약 물리 주소 탐색했는데 메모리에 올라와 있지 않다면, invalid, 올라와 있다면 valid이다.
page default 시 동작
참조할 주소가 메모리에 없으면(Invalid) 아래의 순서로 동작한다.
1. 하드웨어는 page fault exception을 생성한다.
2. OS page fault handler가 clean up 한다.
- OS가 RAM에서 내쫒을 페이지를 정해 디스크로 swap out한다.
- OS는 디스크에서 페이지를 읽어오고 RAM에 올린다.
- OS가 Page table에 매핑 정보를 수정한다.
3. 하드웨어가 다시 매핑을 수행한다.
근데 하드디스크는 엄청나게 느리고, 이 건 오버헤드가 굉장히 큰 동작이다.
TLB

TLB 등장 배경
페이지는 4KB(2^12)이다. 그래서 32비트 컴퓨터의 경우, page table에 배열이 최대 100만개(2^32/2^12) 정도까지 들어갈 수 있다. 따라서, 각 배열의 요소가 4byte이므로 페이지 테이블은 최대 4MB(4byte * 2^20)이 될 수 있다.
그 크기는 상당하다. 또한 각 프로그램마다 각 page table이 존재한다. 이렇듯 용량이 크기때문에, register에 놓을 수도 없고, 메모리에 접근하는 것이기 때문에 하드디스크에 놓을 수도 없다. 이를 그래서 physical memory에 넣어두게 된다. 페이지 테이블에 접근하기 위해 메모리에 접근하고, 다시 전환된 주소를 바탕으로 메모리에 접근하므로 총 2번의 memory access가 필요하게 되는데, 이는 시간이 많이 소요된다. 따라서 이를 해결하기 위해 TLB라는 일종의 캐시 메모리가 있다.
TLB의 역할
자주 사용되는 메모리 접근은 TLB라는 곳에 저장해두고 page테이블을 거치지 않고 바로 주소 변환을 하게 된다. page table에 접근하기 전에 먼저 TLB에 접근해 메모리 접근이 가능한지 확인하고 만약 없는 경우에만 page table에서 일반적인 주소 전환을 하게 된다. TLB에는 논리 주소와 물리 주소가 쌍으로 저장되어 있다.
page 테이블은 각 프로세스마다 있는 것이므로, TLB는 context switch 때에 flush 된다.
Q) TLB는 하나이고 여러 프로세스가 context switch 될 때마다 flush된다고 하는데 process는 병렬적으로 0.xx초단위로 계속 바뀌면서 context switch하는 거아닌가요?? 그렇기에 여러 프로그램이 동시에 동작하는 것처럼 보이는거니까요. 그럼 context switch를 계속하면서 TLB를 계속 flush하면 TLB에 저장된 매핑정보가 계속 초기화되는 것이므로 의미가 없는 것 아닌가요?
현대의 프로세서에서 TLB는 위와 같은 방식으로 flush 되지 않습니다.
cpu의 캐쉬에 저장되는데 프로세스 별로 어드레스가 좀 다를 뿐이예요. 운영체제 별로 다르나 프로세스 별로 valid invalid 를 놓고 비교합니다. 즉 공간이 부족하거나 하면 다른 프로세스의 tlb가 없어지는거예요. 그리고 arm에서는 tlb관련으로 컨텍스트 스위칭마다 ttbr 레지스터가 바뀝니다. 컨텍스트 스위칭 마다 tlb 를 클리어하면 또 메모리에서 가져와야 하는데 캐쉬 히팅률이 매우 떨어지게되고 캐쉬가 공간이 남았는데 지울 필요는 없기 때문입니다. 이게 구형 프로세서는 그렇게 되어있고 요즘 프로세서의 구현은 프로세스의 소유인지 아닌지로 판단한다고 보시면 되겠습니다.
2단계 페이지 테이블
2단계 페이징 등장 이유
32 bit address 사용 시 2**32B(4GB)의 주소 공간이 존재하는 것이다. page가 각 4KB정도 되므로 page table에 page는 총 1만개가 필요하게 된다. 페이지 테이블의 엔트리 각 요소당 4byte가 사용된다면 프로세스는 각각 4MB의 테이블 물리 주소를 필요하게 된다. 용량이 너무 크다. 우리가 100개 프로그램을 running한다면 무려 400MB가 필요한 것이다. 용량은 많이 차지하지만, 대부분 프로그램은 4G의 공간 중 지극히 일부만 사용하므로 만들어놓은 page table의 공간은 심하게 낭비된다. 그렇다고 page table에 원소를 모두 저장하지 않을 수 없다. 쓰임이 낮더라도, 언제 접근할지 모르므로 반드시 필요하기 때문이다. (만약 없다면 어떻게 접근하겠는가) 그래서 등장한 개념이 2단계 페이지 테이블이다. 2단계 페이지 테이블을 쓰면 이러한 문제를 해결할 수 있다.
2단계 페이징의 원리
기존의 페이징에서는 0~4995에 각각의 물리 주소를 매핑했다면, 2단계 페이징에서는 두번째 페이지 테이블의 주소를 매핑해둔다. 실제 접근되지 않는 inner-paging-table이 있다면 outer에서 참조할 2번째 페이지의 주소가 그냥 null 상태로 되어있게 된다.
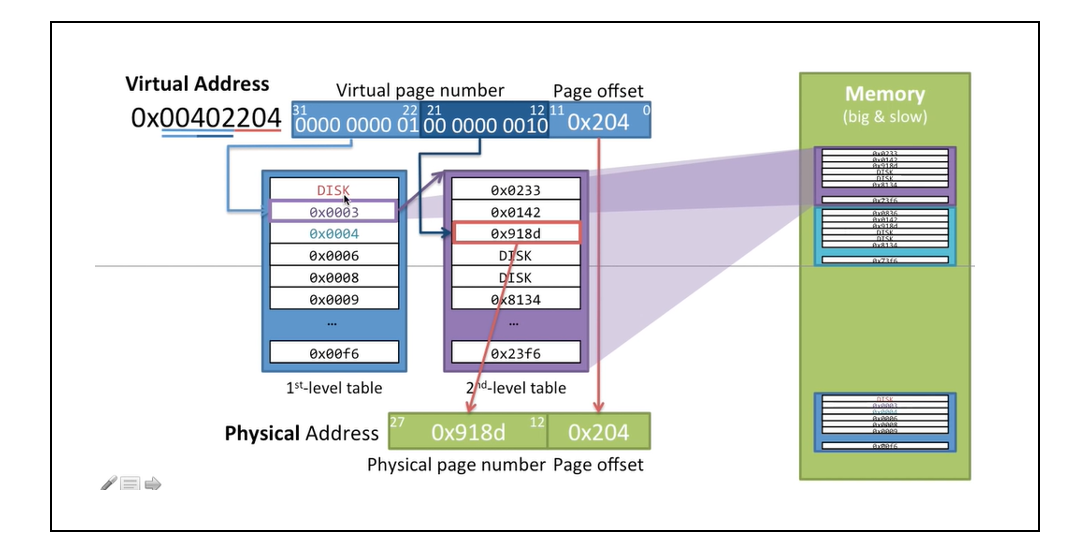
사진을 보며 좀 더 명확히 알아보자.
순서
1) Processor가 31~22의 비트를 참조해 가상 메모리 0x0003에 접근한다. 이는 1단계 페이지이고, 여기에는 2단계 페이지의 주소가 매핑되어 있다.
2) 12~21비트에 있는 값을 참조해 2단계의 몇번째 페이지인지를 참조하게 된다.
Q) 페이지의 개수는 왜 10bit일까?
기존의 1단계 페이징에서는 페이지의 개수 2^20개(20bit), offset이 2^12(12bit)를 통해 물리 주소에 접근했었다. 2단계 페이징에서 offset은 12bit로 동일하지만, 페이지의 개수는 각각 10bit로 차이가 있다. 1단계 페이지는 크기가 4KB이다. 이를 다시 page단위로 쪼개면 어떻게 될까? 아래의 사진을 보자.
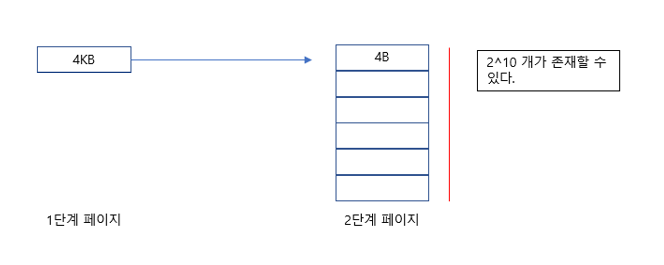
배열의 각 요소 크기는 4B씩이므로 4KB인 1단계 페이지에서는 2단계 페이지를 2^10개로 모두 표현할 수 있다.
2단계 페이징의 장점

1단계 페이징에서는 애플리케이션 하나당 4MB가 필요했다. 하지만 2단계 페이징에서는 실제로 접근하기 위해 4KB + 4KB만 필요하다. 첫번째 페이지 하나, 이와 연결된 두번째 페이지 하나 말이다. 첫번째 페이지는 2번째 페이지의 주소를 모두 나타내야하므로 반드시 있어야한다. 또한 실제 접근하려면 1번 페이지에 매핑된 2번째 페이지가 하나 이상은 존재하고 있어야 물리 메모리를 실제로 참조할 수 있다. 앞서 1번째 페이지에서 매핑되지 않은 부분은 null이라고 했는데, 4KB + 4KB를 제외하고 매핑되지 않아도 되기때문에 null이 가능한것이다.
물론 null인 부분은 하드디스크에서 읽어야하므로 또 시간이 걸릴 것이다. 그렇지만, 프로세스는 대부분 쓰이는 것만 쓰이므로 비슷한 위치의 주소를 참조하는 경우가 많다. 따라서 자주쓰이는 메모리주소만 2단계 페이지로 매핑해놓고, 나머지는 null로 쓰면 시간 효율성은 덜 떨어뜨리면서, 공간 효율성을 많이 높일 수 있게 된다. (얼마나 쓰이는 것만 쓰이면 2단계 페이징이 1단계 페이징보다 더 빠를까 같이 생각하며 이해하면 좋다.)
본 포스팅은 를 바탕으로 작성하였습니다.
참고
'CS > 운영체제' 카테고리의 다른 글
| [운영체제] 물리 메모리 해제와 할당의 동작 원리 (0) | 2022.07.21 |
|---|---|
| [운영체제] 가상메모리 (0) | 2022.07.20 |
| [운영체제] 주소 바인딩과 MMU (0) | 2022.07.18 |
| [운영체제] DeadLock과 그 해결방법 (0) | 2022.07.18 |
| [운영체제] 세마포어와 모니터 (0) | 2022.07.18 |